การตัดคำภาษาไทย : ตัดคำอย่างไร
คำถามพื้นฐานของการตัดคำภาษาไทย คือ อะไรคือคำ กำหนดขอบเขตอย่างไร เรามักคิดว่าปัญหาเรื่องตัดคำทำให้ประมวลผลภาษาไทยยาก ไม่เหมือนภาษาอังกฤษที่เขียนแยกเป็นคำ ๆ ให้แล้ว แต่ความจริง ภาษาอังกฤษก็ยังมีเรื่องของการหาคำที่ประกอบสร้างขึ้นจากคำย่อย ๆ เช่น ice cream, web address, distance learning, on show, by and larage, kick the bucket
การสร้างคำ
การสร้างคำในภาษานั้นทำได้หลากหลายวิธีแล้วแต่ภาษา หลักพื้นฐานคำมาจากการนำหน่วยคำ (morpheme) มา process เป็นคำ (word) หน่วยคำคือหน่วยที่เล็กสุดในภาษาที่มีความหมาย เช่น un- เป็น prefix เติมหน้าหน่วยคำอิสระ happy เป็นคำ unhappy กระบวนการสร้างคำด้วยการเติม affix นี้อาจเป็นกระบวนการที่เรียกว่า inflection คือสร้างรูปคำต่าง ๆ จากหน่วยศัพท์เดียวกัน เช่น สร้าง lives, living จาก live หรือเป็นกระบวนการ derivation คือการสร้างหน่วยศัพท์ใหม่จากเดิม เช่น สร้าง reader, readable จาก read ทั้งสอง process นี้พบมากในภาษาที่เป็น inflectional language ภาษาไทยไม่ได้มีกระบวนการนี้ชัดเจน อาจมองว่ามีบางคำ เช่น การ ความ ผู้ นัก น่า ที่ทำหน้าที่เป็นเหมือน prefix ได้
การซ้ำคำหรือ reduplication ก็เป็นอีกกระบวนการหนึ่งในการสร้างคำ ในภาษาไทยมีการสร้างคำลักษณะนี้มาก ถ้าเป็นการซ้ำรูปเราเรียกคำซ้ำ เช่น เก่า ๆ, แด๋งแดง แต่ถ้าเป็นการซ้ำความหมายเราจะเรียกคำซ้อน เช่น ชั่วร้าย, โหดเหี้ยม บางครั้งก็ซ้ำบางส่วน เช่น หนักอกหนักใจ, ออกดอกออกผล, กระดาษเงินกระดาษทอง คำซ้ำนี้บางตำราก็จัดว่าเป็นประเภทย่อยหนึ่งของการประสมคำ
การประสมคำ
กระบวนการสร้างคำที่พบมากอีกอย่างในภาษาไทยคือ การประสมคำ หรือ compounding คือการนำคำอิสระตั้งแต่สองคำขึ้นไปมาประสมกันแล้วเกิดเป็นคำที่มีความหมายใหม่ที่ต่างจากเดิมหรืออาจมีเค้าความเดิมบ้าง เช่น แม่น้ำ ปากกา ดินปืน กระจกเงา ไม้กวาด ในภาษาอังกฤษก็มีการสร้างคำจากการประสมคำ แต่ส่วนใหญ่จะเขียนติดกันเป็นรูปคำเดียว เช่น firewood, grandfather, boyfriend, แต่บางคำก็ยังเห็นรอยต่อจากการเติม hyphen เช่น dry-clean , washer-dryer บางคำก็ยังเขียนแยกเป็นสองรูป เช่น back seat แต่ถ้าเทียบกับภาษาไทย ซึ่งอาศัยการประสมคำเป็นกลไกหลักในการสร้างคำ คำประสมในภาษาไทยจึงมีใช้มากและซับซ้อนกว่า และเป็นสาเหตุหลักที่ทำให้การตัดคำด้วยคนนั้นมีความไม่คงที่หรือเห็นไม่ตรงกันได้
หนังสือไวยากรณ์ไทยมักยกตัวอย่างคำประสมที่เมื่อรวมกันแล้วมีความหมายใหม่เลย เช่น ลูกเสือ พ่อตา หรือประสมกันแล้วมีความหมายใหม่แต่ยังเห็นเค้าเดิมบ้าง เช่น น้ำแข็ง แม่บ้าน หรือบางคำก็เหมือนจะมีความหมายของคำเดิมทั้งหมด เช่น น้ำหวาน รถบรรทุก ปัญหาที่พบมักเกิดจากการที่คำประสมสามารถประสมกันหลายขั้นได้ เช่น คนขับรถ เป็นคำประสม รถบรรทุก เป็นคำประสม คนขับรถบรรทุก มาจากการประสมที่เอาคำประสม รถบรรทุก มาประสมซ้อนอีกครั้ง
เมื่อจำนวนคำเริ่มมากขึ้น เราก็จะเริ่มลังเลว่าควรให้เป็นคำหรือวลีดีกว่า เช่น คนขับรถแท็กซี่ คนขับรถเมล์ ในเชิงความหมายก็มีลักษณะเดียวกับ คนขับรถ เพราะมีความหมายใหม่ที่เป็นอาชีพหนึ่ง จึงน่าจะให้เป็นคำประสมได้ แต่เมื่อประสมยาวขึ้น เป็น คนขับรถบรรทุกสิบล้อ คนขับรถโดยสารประจำทางปรับอากาศ ก็จะเริ่มไม่แน่ใจแล้วว่าควรตัดเป็นคำเดียวหรือไม่ คำควรจะยาวได้มากแค่ไหน
ปัญหาลักษณะนี้ทำให้การตัดคำด้วยมืออาจเกิดปัญหา เพราะแต่ละคนอาจมองขอบเขตคำต่างกันไป บางคนก็ยอมให้คำประสมยาวมากได้ บางคนก็คิดว่าไม่ควรจะยาวมากไป การสร้าง BEST corpus ที่เป็นข้อมูลตัดคำไทยด้วยมือ ผู้สร้างจึงยึดเกณฑ์ให้ตัดคำให้สั้นเป็นหลัก อะไรที่ตัดแล้วไม่เสียความหมายไปก็ให้ตัดไว้ก่อน วิธีนี้จะช่วยให้การทำงานของคนหลายคนมีความคงที่ได้มากกว่า ด้วยหลักการนี้ คำว่า รถโดยสาร ก็จะตัด รถ|โดยสาร คนขับรถ ก็จะเป็น คน|ขับ|รถ เมื่อยึดหลักนี้ คำประสมที่ไม่ได้มีความหมายต่างจากความหมายรวมของคำย่อยก็จะถูกตัดเป็นหลายคำ ไม้ถูพื้น โต๊ะกินข้าว เหล่านี้ก็ควรตัดเป็นสามคำไปด้วย เพราะสามารถแยกคำได้แบบเดียวกันและความหมายไม่ได้เปลี่ยนไปมาก ยังคงเป็นไม้สำหรับถูพื้น เป็นโต๊ะสำหรับกินข้าว
Aroonmanakun (2007) ก็เสนอความคิดให้ตัดคำเป็นหน่วยที่เล็กสุดที่ไม่เสียความหมายไปก่อนได้ เหมือนเป็นกระบวนการสร้างคำย่อยก่อน แต่ก็เสนอให้มีกระบวนการหา multi-word unit หรือ lexeme ภายหลังด้วย ในลักษณะเดียวกับที่ภาษาอังกฤษเองก็ยังต้องมีการหา multi-word expression ข้อดีของวิธีนี้คือช่วยให้การตัดคำด้วยมือมีความสม่ำเสมอมากกว่า และการตัดคำย่อยก็ไม่ได้มีผลกระทบนักกับงาน NLP อย่าง information retrieval, text classification เพราะคำประสมแม้จะถูกตัดย่อย ก็ยังคงอยู่ในเอกสารนั้นและอยู่ติดกันเสมอ แต่บางงานที่ต้องการใช้ lexeme เช่น machine translation, information extraction, topic modelling ก็อาจต้องมีกระบวนการหา multi-word expression เพื่อรวมคำย่อย ๆ ของคำประสมเป็นหน่วยใหญ่ขึ้นมา
เราควรตัดคำย่อยเสมอ?
คำตอบขึ้นกับหลายปัจจัย ถ้าเราต้องการสร้างคลังข้อมูลตัดคำด้วยมือในเวลาสั้น ๆ ใช้คนจำนวนมากมาช่วย วิธีนี้ก็ช่วยให้คลังข้อมูลที่ได้มีความสม่ำเสมอมากกว่า และถ้างานที่ต้องการนำข้อมูลไปใช้ไม่มีความจำเป็นต้องระบุคำใหญ่ ก็สามารถใช้คลังข้อมูลที่สร้างด้วยวิธีนี้ได้เลย ข้อดีอีกประการคือ จะไม่มีปัญหากับการประมวลผลคำคำประสมที่ยังไม่รู้จักหรือถูกระบุมาก่อน เพราะการระบุหาคำประสมที่ไม่ใช่คำประสมแท้จะไม่ถูกทำในขั้นตอนนี้
คำถามสำคัญอีกคำถาม คือ หากตัดคำย่อยแล้ว เราจะแยกความแตกต่างของคำประสมกับวลีหรือประโยคอย่างไร เพราะการตัดสินว่ารูปคำที่เห็นเป็นคำประสม เป็นวลี หรือเป็นประโยค เป็นเรื่องที่ต้องอาศัยบริบทในการบอก เช่น คนขับรถ อาจเป็นคำประสม หรือเป็นประโยค ก็ได้
มีคนขับรถมาคอยแล้ว คนขับรถ เป็นคำประสมหมายถึง คนคนหนึ่งที่ทำมีอาชีพขับรถ
มีคนขับรถมาจอดแล้ว คนขับรถ เป็นประโยคซ้อนภายใน หมายถึง คนคนหนึ่งขับรถมา
กรณีเช่นนี้ หากเตรียมข้อมูลโดยตัดคำย่อย ข้อมูลที่สร้างจะปรากฏเป็นคำสามคำเหมือนกัน คือ คน|ขับ|รถ วิธีการหนึ่งที่จะช่วยแยกความต่างนี้คือการวิเคราะห์ข้อมูลลงลึกต่อ เช่น ถ้าใช้กรอบการวิเคราะห์ Universal Dependencies วิเคราะห์ ประโยคสองอันนี้มีโครงสร้างและความสัมพันธ์ระหว่างคำที่ต่างกัน ดังนี้
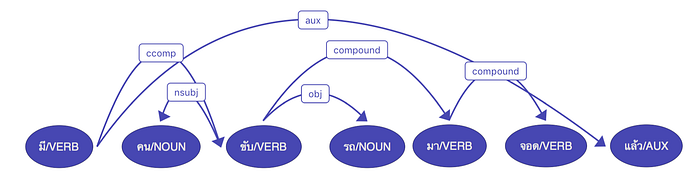
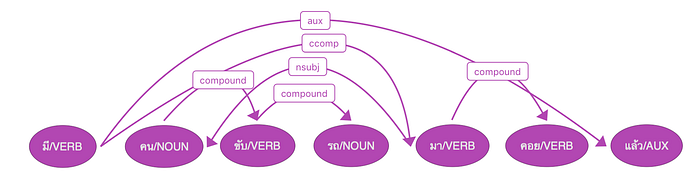
การวิเคราะห์แบบนี้เป็นการผลักภาระงานไปในระดับต่อไป ทำให้การตัดคำเป็นงานที่ง่ายขึ้น โอกาสผิดก็น้อยลง เพราะไม่ต้องมาตัดสินคำประสมเหล่านี้แล้วว่าจะเป็นคำเดียวหรือหลายคำ เพราะได้ตัดเป็นหลายคำไปแล้ว แต่ภาระก็จะไปอยู่กับกระบวนการต่อไป เช่น ให้ parser แยกความสัมพันธ์แบบที่แสดงความต่างตามรูปออกมา หากทำแบบนี้ งาน parser จะซับซ้อนขึ้น เพราะนอกจากจะต้องวิเคราะห์ทาง syntax ที่หาโครงสร้างประโยคว่าคำต่างๆ มาประกอบกันอย่างไร ยังต้องวิเคราะห์ส่วน morphology คือหาโครงสร้างคำประสมเพิ่มมาด้วย ซึ่งทำให้งานยากขึ้นเพราะคำประสมชนิดหนึ่งที่เรียกกว่า synthetic compound จะมีลำดับคำเหมือนประโยค คือ noun-verb-noun ไม้-ถู-พื้น หรือ noun-verb คน-ใช้
ถ้าในแผนงานมีความคิดที่จะ implement parser ลักษณะนี้ต่อ ก็สามารถใช้คลังข้อมูลที่ตัดคำย่อยแบบนี้ได้ โดยมองว่าความต่างของการวิเคราะห์จะถูกผลักภาระไปอยู่ที่ในระดับการหา dependecny parserd tree แต่ก็ต้องยอมรับว่างานจะซับซ้อนขึ้น แต่หากไม่แน่ใจว่ามีเวลาและนักภาษาศาสตร์ที่จะทำส่วนนี้ได้ และต้องการใช้คลังข้อมูลตัดคำเพื่องานต่าง ๆ เลย กรณีนี้ก็อาจจะต้องตัดคำให้ยาวขึ้นบ้าง มองเหมือนว่าการระบุคำประสมเป็นงานลักษณะเดียวกับการระบุ named entity ที่ต้องมีการบอกขอบเขตว่าเริ่มและจบที่ไหน กรณีคำประสม การไม่ตัดคำย่อยเกินไปก็เหมือนเป็นการระบุขอบเขตคำประสมให้กับเครื่อง การตัดคำก็เป็นการตัดคำที่ต้องรวมเอาการแก้ปัญหาคำประสมเหล่านี้ด้วย คือเอาภาระส่วนนี้มาเป็นงานของการตัดคำเลย ซึ่งความจริงก็เป็นแนวคิดดั้งเดิมของการตัดคำที่ต้องการได้คำที่เป็นหน่วยศัพท์หรือ lexeme
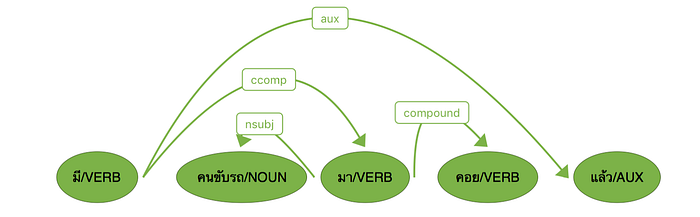
นอกจากนี้ การตัดคำที่แตกต่างกัน ก็ส่งผลต่อการนำข้อมูลไปใช้งานต่อด้วย เช่น หากต้องการสร้าง word2vec จากคลังข้อมูลที่ตัดด้วยเป็นคำย่อย เช่น ตัด กลางคืน เป็นสองคำ เมื่อแปลงเป็น word2vec จะไม่มีเว็กเตอร์ของ กลางคืน แต่มีของคำ กลาง กับ คืน ดังนี้ (ข้อมูลจากการใช้ BEST corpus)
most_similar(“กลาง”) => [‘เหนือ’, ‘เที่ยง’, ‘อีสาน’, ‘ล่าง’, ‘บ่าย’, ‘ใหญ่’, ‘สี่’, ‘สาม’, ‘นี้’, ‘แต่ละ’]
most_similar(“คืน”) => [(‘ดึก’, ‘วัน’, ‘วาน’, ‘เช้า’, ‘เดือน’, ‘บ่าย’, ‘มื้อ’, ‘อาทิตย์’, ‘พรุ่ง’, ‘ค่ำ’ ]
หากเราไม่รู้มาก่อนว่ามีการตัดคำแบบนี้ ก็อาจสงสัยว่า ทำไม กลาง จึงคล้ายกับ เที่ยง หรือ บ่าย ได้ ผลที่ออกมาแบบนี้ เพราะ กลาง ในคลังข้อมูลนี้มีทั้ง กลาง ที่สัมพันธ์กับทิศ ตำแหน่ง ขนาด และ กลาง ที่เป็นคำเกิดหน้า วัน กับ คืน จึงสัมพันธ์กับเวลา เที่ยง บ่าย
แต่หากในคลังข้อมูลไม่ได้ตัด กลางคืน เป็นสองคำ ก็จะได้เว็กเตอร์ของทั้งสามคำ ซึ่งแสดงชุดคำที่สัมพันธ์กันต่างออกไป ดังนี้ (ข้อมูลจากการใช้ Thai National Corpus)
most_similar(“กลางคืน”) => [‘กลางวัน’, ‘หัวค่ำ’, ‘บ่าย’, ‘ดึก’, ‘เช้ามืด’, ‘เช้าตรู่’, ‘ค่ำ’, ‘ตอนเช้า’, ‘เที่ยง’, ‘ตอนเย็น’]
most_similar(“กลาง”) => [‘ใต้’, ‘ล่าง’, ‘ปลาย’, ‘บน’, ‘ตรงกลาง’, ‘ใหญ่’, ‘ใกล้’, ‘กึ่งกลาง’, ‘ริม’, ‘นอก’]
most_similar(“คืน”) => [‘วัน’, ‘เช้า’, ‘ปี’, ‘คราว’, ‘เดือน’, ‘งวด’, ‘กลับบ้าน’, ‘สัปดาห์’, ‘คืนชีพ’, ‘ต้นเงิน’ ]
การนำคลังข้อมูลตัดคำไปสร้าง word2vec ใช้งานต่อ จึงควรเข้าใจว่าข้อมูลที่ใช้นั้นมีลักษณะแบบไหน และเว็กเตอร์ที่ได้จะเป็นแบบใด หรือในทางตรงข้าม ความต้องการที่จะใช้ word2vec ที่แสดงความสัมพันธ์ของคำแบบไหน ก็จะเป็นปัจจัยให้เลือกว่าควรตัดคำแบบใด
ทำอย่างไรจึงจะตัดคำประสมได้คงที่
หากเลือกแนวทางตัดคำใหญ่ขึ้น คำถามเดิมก็จะกลับมาว่าทำอย่างไร จึงจะทำให้มีการตัดคำด้วยมือแบบสม่ำเสมอ ข้อเสนอคือให้เดินสายกลาง ปัญหาที่เกิดความไม่สม่ำเสมอมักจะมาจากการตัดคำที่ยาวเกินไป ดังนั้น ถ้าระบุขอบเขตว่า คำประสมที่ตัดนั้นไม่ควรยาวมากไป
คำประสมโดยทั่วไปมักประกอบด้วยคำ 2–3 คำ ยกเว้นคำซ้ำคำซ้อนที่อาจยาวกว่านั้นได้ คำประสมทั่วไป เช่น ไม้ถูพื้น โต๊ะกินข้าว อาหารเย็น สมุดพก ฯลฯ คำเหล่านี้โอกาสที่จะพบใช้แบบไม่ใช่คำประสมนั้นแม้จะนึกตัวอย่างออกได้ เช่น เขานั่งโต๊ะกินข้าวกับพ่อแม่ โต๊ะกินข้าว จะไม่ใช่คำประสมแล้ว แต่โอกาสแบบนี้ไม่น่าจะเกิดจริงนัก เพราะเรามักจะเลี่ยงพูดไปแบบอื่นหรือไม่ เช่น เขานั่งกินข้าวกับพ่อแม่ เสียมากกว่า ดังนั้น การไม่รวบคำประสมไว้ในข้อมูลที่เห็น ก็เป็นการปล่อยโอกาสที่จะกำหนดขอบเขตคำประสมทั่วไปที่พบใช้มากในภาษาไทย แล้วต้องมาแก้ปัญหาภายหลัง เช่น อาจต้องมาระบุคำประสมแบบเดียวกับที่ระบุชื่อเฉพาะ
ส่วนการคุมการทำข้อมูลให้ตรงกัน ควรสร้าง online compound glossary ให้คนทำข้อมูลเห็นร่วมกัน เพื่อให้มีการตัดคำได้ตรงกัน อาจใช้ webboard เพื่อเปิดประเด็นคำถามและแลกเปลี่ยนความเห็นจนได้ข้อสรุป วิธีการเหล่านี้ก็จะช่วยให้การตัดคำประสมมีความสม่ำเสมอได้ เหมือนคนที่ทำงานแปลที่ต้องแบ่งข้อมูลช่วยกันแปล ก็จะใช้เทคโนโลยีของ machine aided translation ที่ช่วยให้สามารถแชร์ glossary ร่วมกัน มีโปรแกรมช่วยตรวจความสม่ำเสมอของการแปลจากผู้แปลหลาย ๆ คนได้
NEXT : ประเมินผลอย่างไร
อ้างอิง
Aroonmanakun, W. 2007. Thoughts on Word and Sentence Segmentation in Thai. In Proceedings of the Seventh Symposium on Natural Language Processing, Dec 13–15, 2007, Pattaya, Thailand. 85–90
Kosawat, Krit & Boriboon, Monthika & Chootrakool, Patcharika & Chotimongkol, Ananlada & Klaithin, Supon & Kongyoung, Sarawoot & Kriengket, Kanyanut & Phaholphinyo, Sitthaa & Purodakananda, Sumonmas & Thanakulwarapas, Tipraporn & Wutiwiwatchai, Chai. (2009). BEST 2009: Thai Word Segmentation Software Contest. 83–88.
Universal Dependencies http://universaldependencies.org/
ตัวอย่างข้อมูล word2vec มาจากการทดลองใช้ BEST และ TNC