การทำ Topic modeling
Topic modeling คืออะไร
Topic modeling เป็นวิธีการทางสถิติแบบหนึ่งที่ใช้เพื่อค้นพบ topic หรือ “หัวข้อ” ที่แฝงอยู่ในเอกสาร. เป็นวิธีการที่นิยมใช้ในการวิเคราะห์ข้อมูลเอกสาร เพราะทำให้เห็นความสัมพันธ์ภายในของข้อมูลที่ไม่มีโครงสร้างอย่างข้อมูลภาษาได้ จึงเป็นงานที่ศาสตร์ต่าง ๆ ใช้ศึกษาทำความเข้าใจข้อมูลของหัวข้อต่าง ๆ ในศาสตร์ได้. Topic modeling เป็นการเรียนรู้ด้วยเครื่องแบบไม่มีการชี้แนะ (unsupervised learning) โดยอาศัยการเกิดร่วมกันของคำในเอกสารเพื่อมองหาความหมายที่ซ่อนเร้นอยู่ภายในข้อความ. เราสามารถใช้ topic modeling เพื่องานประมวลผลภาษาต่าง ๆ เช่น การจัดประเภทเอกสารตามหัวข้อ การสรุปคำสำคัญในหัวข้อ
“หัวข้อ” ที่ได้คือกลุ่มของคำที่มีความหมายอยู่ในกลุ่มกัน โดยคำนวณมาจากความถี่ของการปรากฏร่วมกันของคำภายในเอกสารต่าง ๆ อัลกอริทึมที่มักใช้ในงาน topic modeling เช่น Latent Dirichlet Allocation (LDA เสนอโดย Pritchard, Stephens, and Donnelly 2000 และใช้ใน Machine learning โดย Blei, Ng, and Jordan 2003), และ Latent Semantic Analysis (LSA; Dumais et al. 1988) อัลกอริทึมเหล่านี้ทำงานโดยอาศัยหลักการสร้างเมทริกซ์ดูการกระจายตัวของคำต่าง ๆในเอกสารสร้างเป็น Document-Term matrix ออกมา สมติว่ามีเอกสาร d ชิ้น และมีจำนวนรูปศัพท์ในเอกสารทั้งหมด n ศัพท์ ก็จะสามารถสร้างเมทริกซ์ขนาด d x n ได้ ซึ่งเมทริกซ์ d x n นี้ สามารถมองได้ว่าเป็นผลมาจากการคูณกันของเทริกซ์ขนาด d x k และ k x n ได้ ซึ่งถ้าเรามองว่า k นี้คือจำนวน topic หรือหัวข้อที่มีในข้อมูล เราก็สามารถหาคำตอบนี้ได้ เพราะจะได้ผลที่บอกว่า คำที่เกี่ยวข้องกับหัวข้อต่างๆ (1..k) มีคำอะไรบ้าง เกี่ยวข้องมากน้อยเพียงใด ส่วนผลอีกตารางจะบอกว่าเอกสารแต่ละชิ้นมีความเกี่ยวข้องกับหัวข้อต่างๆ กี่เรื่องและเกี่ยวข้องมากน้อยแค่ไหน

ทำไมจึงหากลุ่มคำในหัวข้อได้
Topic modeling ไม่ต้องอาศัยความรู้ทางภาษาศาสตร์โดยตรงมาวิเคราะห์ข้อมูลภาษา ไม่ต้องวิเคราะห์โครงสร้างประโยค ไม่ต้องรู้ว่าอะไรเป็นประธานหรือกรรม มองข้อมูลภาษาแบบไม่สนใจลำดับคำหรือโครงสร้าง มองข้อมูลภาษาเป็นเพียงกล่องใส่คำหรือ bag of words ที่มีคำต่าง ๆ อยู่ในกล่องนั้น. แต่ด้วยธรรมชาติของภาษาที่คำมีความหมาย เมื่อเราพูดถึงหัวข้อใดหัวข้อหนึ่ง เช่น พูดเรื่องการสร้างคลังข้อมูลภาษา ก็จะมีคำเหล่านี้ปรากฏซ้ำ ๆ ในตัวบท ได้แก่ ตัวบท การสร้าง ตัวแทนภาษา ขนาด การกำกับข้อมูล ฯลฯ เอกสารหรือตัวบทหนึ่งก็มักมีหัวข้อที่กล่าวถึงไม่กี่หัวข้อในนั้น เอกสารที่กล่าวถึงหัวข้อต่างกัน คำที่ปรากฏในเอกสารก็จะต่างกัน. ด้วยลักษณะธรรมชาติเช่นนี้ เมื่อเราแจกแจงการปรากฏของคำเนื้อหาในเอกสารทั้งหมดในรูปตาราง Document-Term matrix แต่ละ Document ก็มีชุดลำดับความถี่ของคำไม่เหมือนกัน ชุดลำดับความถี่คำนี้ก็คือเว็กเตอร์ที่ใช้แทน Document นั้น. Document ที่คล้ายกันก็จะมีเว็กเตอร์ที่ใกล้กัน. ในทางกลับกัน หากมองคำจากชุดลำดับความถี่ที่พบในแต่ละเอกสาร ก็จะได้เว็กเตอร์ที่ใช้แทนคำต่าง ๆ คำที่มีความหมายใกล้เคียงกันก็จะมีเว็กเตอร์ที่ใกล้กัน.
ในการทำ topic modeling เนื่องจากความสนใจอยู่ที่การปรากฏของคำเนื้อหาภายในตัวบท การเตรียมข้อมูลหรือ preprocessing จึงมีการตัดคำไวยากรณ์ออกให้เหลือคำเนื้อหา และหากเป็นภาษาที่มีวิภัติปัจจัยก็มีการแปลงรูปคำจริงให้เป็นรูปพื้นฐานก่อน. การทำ topic modeling ในข้อมูลเอกสารสามารถทำได้หลากหลายวิธี จะใช้โปรแกรมสำเร็จรูปที่มีผู้พัฒนา หรือเขียนโปรแกรมโดยใช้ library ในภาษา Python หรือ R ก็ได้ หรือใช้ generative AI อย่าง ChatGPT ช่วยวิเคราะห์คำนวณให้ก็ได้
โปรแกรม Topic modeling
โปรแกรม Topic modeling เป็นโปรแกรมสำเร็จรูปสำหรับวิเคราะห์เอกสารต่าง ๆ ที่มีอยู่เพื่อมองหาว่าในเอกสารนั้นมี topic หรือหัวข้ออะไรบ้าง และหัวข้อนั้น ๆ แสดงออกผ่านทางรูปคำอะไรบ้าง มีโปรแกรมที่สามารถดาวน์โหลดมาใช้ได้ฟรีทั้งบน Windows และ Mac เช่น โปรแกรมของ Jonathan Scott Enderle ที่ทำ GUI สำหรับ MALLET Topic Modeling (https://github.com/senderle/topic-modeling-tool) ซึ่งช่วยให้การใช้งาน MALLET topic modeling (http://mallet.cs.umass.edu/topics.php) ทำได้สะดวกขึ้น หรือโปรแกรม Topic modeling ของ Stanford สามารถดาวน์โหลดได้ที่ https://nlp.stanford.edu/software/tmt/tmt-0.4/ ในที่นี้จะเลือกใช้โปรแกรมของ Enderle ที่พัฒนาด้วยภาษา Java และทำเป็น app ให้ใช้ได้ทั้งบน Windows และ Mac OSX
เพื่อให้เห็นผลที่ชัดเจนการการทำ topic modeling ในตัวอย่างนี้จึงทดลองใช้ไฟล์ข้อมูลจากโดเมนที่แตกต่างกันชัดเจนจำนวน 24 ไฟล์ ได้แก่ รายงานภาวะเศรษฐกิจ 7 ไฟล์, เอกสารทรัพย์สินทางปัญญา 7 ไฟล์, คำกล่าวสุนทรพจน์ 7 ไฟล์, นิยายของเจน ออสติน 3 เล่ม แล้วใช้โปรแกรม GUI ของ MALLET Topic modeling กับข้อมูลชุดนี้ โดยตั้งจำนวน topic ไว้ที่ 10 topic เมื่อกำหนด input directory และ output directory แล้ว ผลลัพธ์ที่ได้จะเก็บในรูป csv และ html ใน folder “output_csv” และ “output_html” โปรแกรมจะบอกว่า topic ต่าง ๆ นั้นมีคำอะไรที่สำคัญใน topic นั้น โดยให้ชื่อเป็น topic 0-n ตามจำนวน topic ที่ตั้งไว้ตอนต้น
ไฟล์ top_in_word.csv แสดงถึงรายการคำสำคัญในแต่ละ topic ที่วิเคราะห์มาโดยเรียงตามลำดับความสำคัญของคำต่าง ๆ. ถ้าต้องการสำรวจผลที่ได้ว่า จำนวน topic ที่กำหนดและจำนวนรอบการ run นั้นให้ผลดีพอหรือยัง ก็ควรเปิด folder output_html เพราะมี link ที่โยงข้อมูลให้คลิกดูได้สะดวกมากกว่า ส่วนใน output_csv จะเห็นไฟล์ csv ที่สรุปความสัมพันธ์ระหว่าง word, topic, doc เมื่อเปิดดูไฟล์ top_in_doc.csv จะเห็นว่าแต่ละ doc นั้นมีเนื้อหาเกี่ยวกับ topic อะไรมากน้อยกว่ากันโดยคำนวณมาเป็นน้ำหนัก. จากข้อมูลที่นำมาทดสอบ จะเห็นว่าไฟล์เนื้อหาทางด้านเศรษฐกิจถูกจัดว่ามีน้ำหนักเป็น topic 7 และ 6 มากสุด (ดูรูปข้างล่าง), ไฟล์สุนทรพจน์มีเนื้อหาหนักไปทาง topic 0, ไฟล์นวนิยายมีเนื้อหาเป็น topic 9. การระบุว่า topic นั้นเกี่ยวกับเรื่องหรือประเด็นอะไร เป็นสิ่งที่ผู้วิจัยต้องใช้ความรู้ของตนระบุชื่อหัวข้อเอง

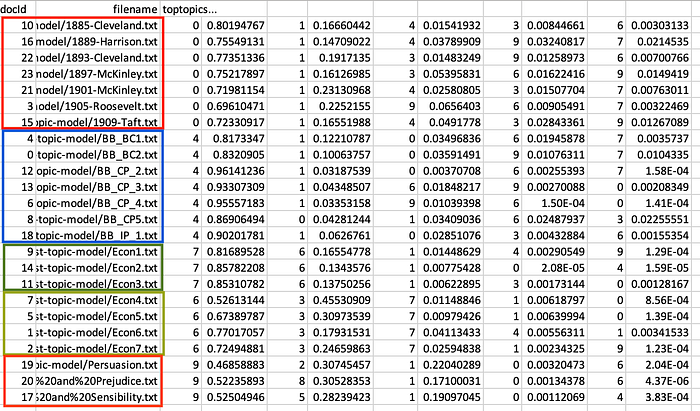
ผลจากการใช้โปรแกรม Topic modeling นี้ทำให้เห็นว่าโมเดลสามารถจัดกลุ่มของเอกสารตามหัวข้อที่พบได้ และยังเห็นว่าเอกสารด้านเศรษฐศาสตร์นั้นยังแยกเป็นสองหัวข้อคือ 6 และ 7 โดยที่ 6 เหมือนเป็นเรื่องดัชนีทางเศรษฐกิจ ส่วน 7 เป็นเหมือนรายงานการตลาด
การใช้ Python ทำ topic modeling
Python เป็นภาษาหนึ่งที่มี library สำหรับทำ topic modeling ตัวอย่างพร้อมคำอธิบาย Python code ที่ใช้ทำ topic modeling ในที่นี้ดัดแปลงมาจาก code ที่ให้ไว้ใน Pykes, K. (2023). What is Topic Modeling? เมื่อทดลองนำ code จากเว็บนี้มาปรับใช้กับข้อมูลชุดเดียวกับข้างบน. โดยให้หา 10 topic และแสดงคำสำคัญ 9 คำแรกออกมาจะได้ผลตามที่แสดง (ใน code มีให้ใช้ LSA model ด้วย)
ใน code ส่วนแรกเป็นการอ่านไฟล์แต่ละไฟล์มาและใส่ไว้ใน corpus. ส่วนต่อมาเป็นการใช้ NLTK เพื่อ clean ข้อมูลโดยกำจัดคำที่ไม่ใช่คำเนื้อหาออกหรือที่เรียกว่า stopwords ลบเครื่องหมายวรรคตอน เปลี่ยนตัวพิมพ์ใหญ่เป็นตัวพิมพ์เล็ก และแปลงคำให้เป็นรูปพื้นฐาน (lemmatize). เมื่อ clean ข้อมูลแล้ว ขั้นต่อไปคือการสร้าง id คำและสร้าง document-term matrix จากนั้นจึงใช้ LdaModel กับเมทริกซ์ที่สร้างมา
import glob
# read all .txt files
corpus = []
fname = []
for file in glob.glob("*.txt"):
with open(file, encoding='utf-8', errors='ignore') as f:
contents = f.read()
fname.append(file)
corpus.append(contents)
# Code source: https://www.analyticsvidhya.com/blog/2016/08/beginners-guide-to-topic-modeling-in-python/
# clean data
import string
import nltk
nltk.download('stopwords')
nltk.download('wordnet')
nltk.download('omw-1.4')
from nltk.corpus import stopwords
from nltk.stem.wordnet import WordNetLemmatizer
# remove stopwords, punctuation, and normalize the corpus
stop = set(stopwords.words('english'))
exclude = set(string.punctuation)
lemma = WordNetLemmatizer()
def clean(doc):
stop_free = " ".join([i for i in doc.lower().split() if i not in stop])
punc_free = "".join(ch for ch in stop_free if ch not in exclude)
normalized = " ".join(lemma.lemmatize(word) for word in punc_free.split())
return normalized
clean_corpus = [clean(doc).split() for doc in corpus]
from gensim import corpora
# Creating document-term matrix
dictionary = corpora.Dictionary(clean_corpus)
doc_term_matrix = [dictionary.doc2bow(doc) for doc in clean_corpus]
'''
# LSA model
from gensim.models import LsiModel
lsa = LsiModel(doc_term_matrix, num_topics=10, id2word = dictionary)
for x in lsa.print_topics(num_topics=10, num_words=8:
print(x)
'''
# LDA model
from gensim.models import LdaModel
lda = LdaModel(doc_term_matrix, passes=20, iterations = 400, num_topics=10, id2word = dictionary)
# Results
for x in lda.print_topics(num_topics=10, num_words=9):
print(x)
i=0
for x in lda.get_document_topics(doc_term_matrix):
print(fname[i],x)
i = i+1(0, '0.021*"year" + 0.015*"percent" + 0.013*"rate" + 0.012*"price" + 0.011*"market" + 0.008*"growth" + 0.006*"increase" + 0.006*"first" + 0.006*"1999"')
(1, '0.001*"heritage" + 0.001*"wellbeing" + 0.001*"aright" + 0.001*"faced" + 0.001*"ours" + 0.001*"founded" + 0.001*"child" + 0.001*"manlier" + 0.001*"manfully"')
(2, '0.012*"mr" + 0.011*"anne" + 0.010*"could" + 0.008*"would" + 0.007*"captain" + 0.006*"elliot" + 0.005*"must" + 0.005*"one" + 0.005*"lady"')
(3, '0.020*"district" + 0.018*"sale" + 0.012*"contact" + 0.012*"report" + 0.011*"price" + 0.010*"activity" + 0.010*"reported" + 0.009*"demand" + 0.007*"new"')
(4, '0.000*"mr" + 0.000*"could" + 0.000*"would" + 0.000*"much" + 0.000*"elinor" + 0.000*"sister" + 0.000*"first" + 0.000*"one" + 0.000*"said"')
(5, '0.000*"mr" + 0.000*"elinor" + 0.000*"could" + 0.000*"would" + 0.000*"sister" + 0.000*"it" + 0.000*"much" + 0.000*"every" + 0.000*"marianne"')
(6, '0.024*"copyright" + 0.023*"right" + 0.022*"work" + 0.012*"information" + 0.012*"law" + 0.010*"confidence" + 0.009*"author" + 0.008*"may" + 0.007*"owner"')
(7, '0.015*"mr" + 0.009*"could" + 0.008*"would" + 0.007*"it" + 0.006*"said" + 0.005*"elizabeth" + 0.005*"elinor" + 0.005*"much" + 0.005*"must"')
(8, '0.000*"year" + 0.000*"percent" + 0.000*"rate" + 0.000*"mr" + 0.000*"would" + 0.000*"market" + 0.000*"price" + 0.000*"could" + 0.000*"elizabeth"')
(9, '0.010*"people" + 0.009*"government" + 0.008*"upon" + 0.006*"law" + 0.006*"state" + 0.005*"must" + 0.005*"shall" + 0.005*"public" + 0.005*"may"')
BB_BC2.txt [(5, 0.9997567)]
Econ6.txt [(4, 0.99990094)]
Econ7.txt [(4, 0.9999085)]
1905-Roosevelt.txt [(0, 0.50624543), (1, 0.49198592)]
BB_BC1.txt [(0, 0.022399377), (5, 0.9773712)]
Econ5.txt [(4, 0.9999008)]
BB_CP_4.txt [(0, 0.87681764), (1, 0.12267691)]
Econ4.txt [(4, 0.99992263)]
BB_CP5.txt [(0, 0.6842176), (1, 0.28131), (5, 0.03423887)]
Econ1.txt [(6, 0.9948662)]
1885-Cleveland.txt [(0, 0.2361853), (9, 0.7628313)]
Econ3.txt [(6, 0.99990684)]
BB_CP_2.txt [(0, 0.9991562)]
BB_CP_3.txt [(0, 0.99949235)]
Econ2.txt [(6, 0.99990493)]
1909-Taft.txt [(0, 0.34673992), (4, 0.03866534), (9, 0.60896504)]
1889-Harrison.txt [(0, 0.58897597), (1, 0.396636), (6, 0.014057016)]
Sense and Sensibility.txt [(7, 0.99998504)]
BB_IP_1.txt [(0, 0.9845775), (5, 0.014956588)]
Persuasion.txt [(1, 0.37154853), (7, 0.62843275)]
Pride and Prejudice.txt [(7, 0.9999854)]
1901-McKinley.txt [(0, 0.99917203)]
1893-Cleveland.txt [(0, 0.7654154), (3, 0.23377733)]
1897-McKinley.txt [(0, 0.99954206)]
ผลที่แสดงออกมาส่วนแรกเป็นรายการคำสำคัญของแต่ละ topic ส่วนที่สองเป็นไฟล์และน้ำหนัก topic ของไฟล์นั้น ซึ่งจะเห็นการจัดกลุ่มไฟล์ข้อมูล Econ1-Econ3, Econ4-Econ7 เหมือนข้างต้น แต่ยังเห็นความต่างเพิ่มเติมในไฟล์กลุ่มทรัย์สินทางปัญญาและไฟล์คำกล่าวสุนทรพจน์
การใช้ R ทำ topic modeling
R เป็นอีกโปรแกรมที่มี library สำหรับทำ topic modeling. ตัวอย่าง code นี้ได้มาจากเว็บเพจ A gentle introduction to topic modeling using R. ขั้นตอนต่าง ๆ ก็เหมือนกับโปรแกรม Python คือ อ่านข้อมูลไฟล .txt, clean ข้อมูล, สร้าง document-term matrix, และสร้างโมเดล LDA. จากนั้นจึงพิมพ์ผลที่ได้ออกมา
#Topic modeling for R
## coding from https://eight2late.wordpress.com/2015/09/29/a-gentle-introduction-to-topic-modeling-using-r/
library(tm)
library(topicmodels)
# read all *.txt and create a corpus
setwd("/Users/awirote/Dropbox/Corpus/test-topic-model")
filenames <- list.files(getwd(),pattern="*.txt")
files <- lapply(filenames,readLines)
docs <- Corpus(VectorSource(files))
# clean documents
docs <-tm_map(docs,content_transformer(tolower))
docs <- tm_map(docs, removePunctuation)
docs <- tm_map(docs, removeNumbers)
docs <- tm_map(docs, removeWords, stopwords("english"))
docs <- tm_map(docs, stripWhitespace)
# create document-term matrix
dtm <- DocumentTermMatrix(docs)
# save word frequency
rownames(dtm) <- filenames
freq <- colSums(as.matrix(dtm))
write.csv(freq,"word_freq.csv")
ord <- order(freq,decreasing=TRUE)
write.csv(freq[ord],"word_freq_sort.csv")
# set up parameter for LDA and create LDA model
burnin <- 4000 ### set burn in 4000
iter <- 2000 ### set iteration
thin <- 500
seed <- list(2003,5,63,2456,765) ## random 5 numbers for
nstart <- 5 ## use 5 different starting point
best <- TRUE
k<-10 ### define number of topics
ldaOut <-LDA(dtm,k, method="Gibbs", control=list(nstart=nstart, seed = seed, best=best, burnin = burnin, iter = iter, thin=thin))
# print results
ldaOut.topics <- as.matrix(topics(ldaOut))
write.csv(ldaOut.topics,file=paste("LDAGibbs",k, "DocsToTopics.csv"))
ldaOut.terms <- as.matrix(terms(ldaOut,30))
write.csv(ldaOut.terms,file=paste("LDAGibbs",k, "TopicsToTerms.csv"))
topicProbabilities <- as.data.frame(ldaOut@gamma)
write.csv(topicProbabilities,file=paste("LDAGibbs",k, "TopicProbabilities.csv"))ผลที่ได้ในไฟล์ TopicsToTerms.csv เป็นรายการคำสำคัญในแต่ละ topic ตามลำดับความสำคัญ ส่วนไฟล์ DocsToTopics.csv ให้ข้อมูลว่าไฟล์นั้นมีน้ำหนัก topic ใดมากที่สุด หากต้องการดูค่าน้ำหนักหรือ probability จริงให้ดูที่ไฟล์ DocsToTopics.csv
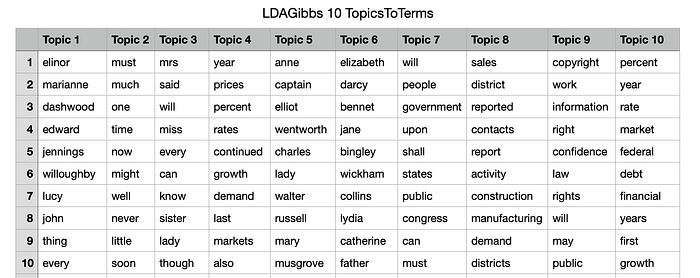
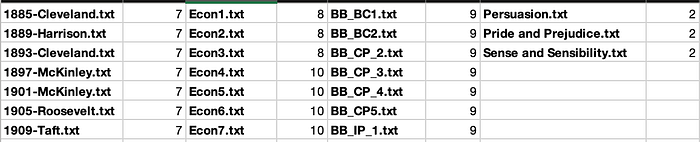
ผลที่ได้จากโปรแกรม Python และ R ไม่ได้เหมือนกับที่ใช้โปรแกรมแรกทุกประการ เพราะการตั้งพารามิเตอร์ในการทำงานไม่ได้เหมือนกัน แต่ทิศทางก็ไปในลักษณะเดียวกัน คือไฟล์จากโดเมนเดียวกันก็จะจัดกลุ่มเดียวกัน บางไฟล์อาจมีน้ำหนัก topic สำคัญมากกว่าหนึ่ง topic ก็ได้
การใช้ ChatGPT ทำ Topic modeling
ใน ChatGPT Plus เราสามารถ upload ไฟล์ข้อมูลทั้งหมดเป็น zip ไฟล์ไปแล้วใช้ Advanced Data Analysis (ADA) ช่วยวิเคราะห์ topic modeling ได้ เริ่มต้นด้วยการสั่งให้วิเคราะห์หา 10 topics ซึ่ง ADA ก็จะ unzip และดูข้อมูลภายในพบว่ามี text files จำนวนหนึ่ง
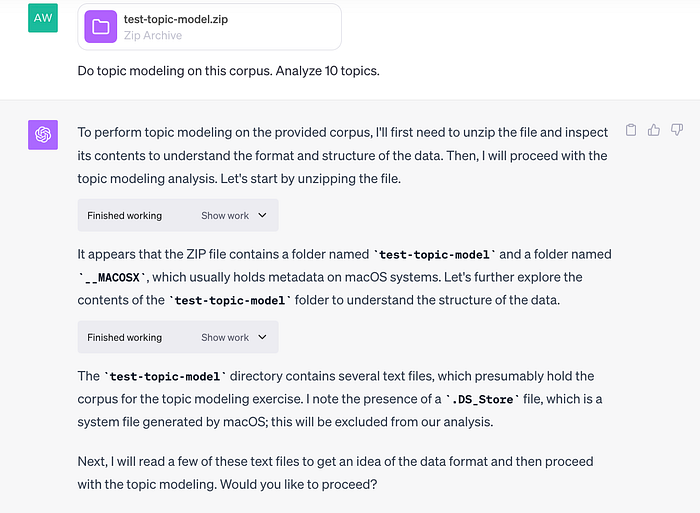
เมื่อตอบ yes ให้วิเคราะห์ต่อ ADA ก็ใช้อัลกอลิทึม LDA หา 10 topics และรายงานว่า topic จำนวนหนึ่งซ้ำซ้อนไม่สามารถแยกขาดกัน

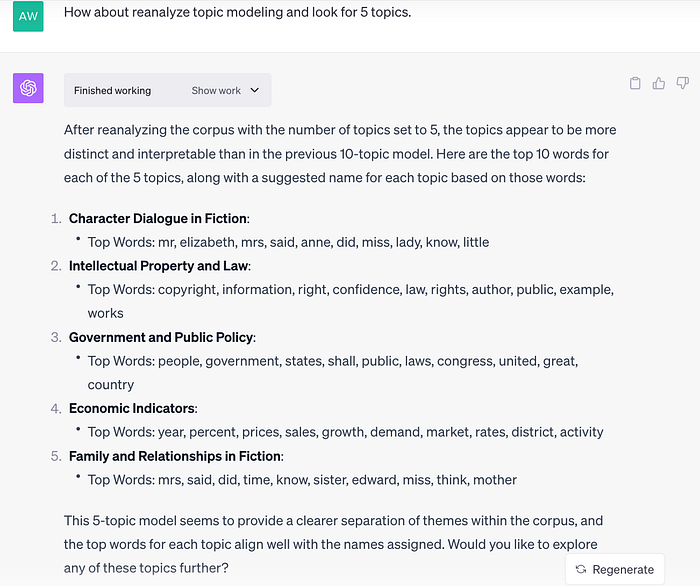
เมื่อสั่งให้แสดงคำสำคัญใน 10 topics นั้น ADA ก็ยังแสดงให้เห็นเพียง 5 topics และบอกว่าแต่ละ topic เป็นหัวเรื่องอะไร

ในที่นี้จึงสั่งให้ทำงานใหม่และตั้งค่าให้หา 5 topics จึงได้หัวข้อและคำของ topic ต่างๆ ตามที่เห็นนี้
เมื่อสั่งต่อให้ระบุว่าไฟล์ไหนควรจัดอยู่ใน topic ไหน ADA ก็แจงออกมาให้ได้ ซึ่งจะเห็นว่านิยายที่ถูกแยกออกจากกลุ่มคือ Sense and Sensibility เพราะมีคำที่เป็นเรื่องเกี่ยวกับความสัมพันธ์ครอบครัวชัดกว่า

จากนั้นจึงสั่งให้ save ผลที่ได้เป็นไฟล์ โดยสั่งให้แสดงคำสำคัญในแต่ละ topic และแสดงว่าแต่ละไฟล์ควรจัดอยู่ใน topic ไหนพร้อมทั้งค่าน้ำหนักของ topic นั้น ๆ ด้วย ซึ่งก็เห็นการจัดกลุ่มเป็นไปตามเนื้อหาของไฟล์
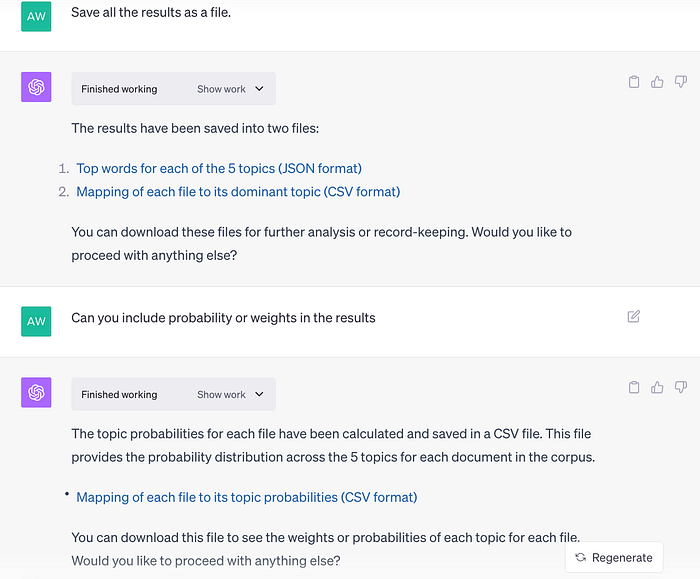
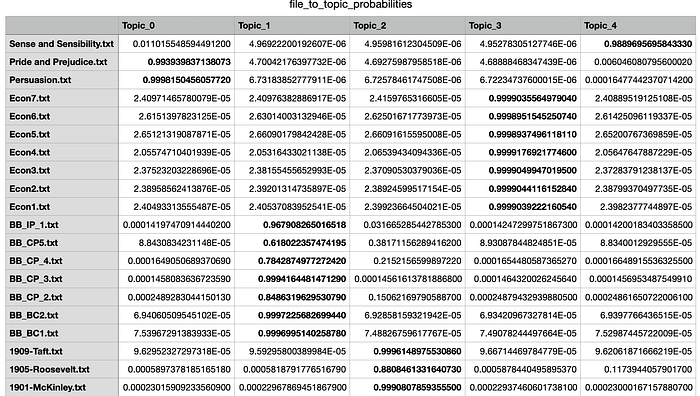
Topic modeling บนไฟล์หนังสือหนึ่งเล่ม
การทำ Topic modeling ไม่ได้จำเป็นต้องทำกับข้อมูลหลาย ๆ ไฟล์ อาจทำบนข้อมูลไฟล์เดียวอย่างไฟล์หนังสือได้ เพราะในการทำงานจะมีการแบ่งตัวบทเป็นส่วน ๆ อยู่แล้ว. เมื่อทดลองให้ทำ topic modeling กับข้อมูลใหม่ที่เป็นหนังสือหนึ่งเล่ม และให้เริ่มต้นด้วยการให้หาจำนวนหัวข้อที่เหมาะสมให้ก่อน ADA ก็พยายามทดลองทำให้

ADA จะเริ่มตามขั้นตอนคือทำ preprocessing แล้วจึงแปลงตัวบทเป็นเว็กเตอร์ก่อนจะใช้ LDA ซึ่งก็สามารถอ่านข้อมูลและแยกย่อหน้าออกมา 3,053 ย่อหน้าเพื่อทดลองหาจำนวน topic ที่เหมาะสม แต่ระหว่างทางจะเห็นข้อความแจ้งว่าติดขัดด้วยเหตุต่าง ๆ เช่น ไม่สามารถติดตั้ง library บางตัวเพิ่มได้ ใช้เวลาในการทำงานนานเกินไป ฯลฯ

เมื่อลองปรับเปลี่ยนวิธีการต่าง ๆ ตามที่ ADA แนะให้ลองก็ยังทำไม่ได้ผล จึงตัดสินใจให้ทำ topic modeling โดยตั้งจำนวน 10 topic ไปเลย ซึ่ง ADA ก็สามารถทำงานออกมาให้ได้ และแจกแจงคำสำคัญในแต่ละ topic มาให้. ข้อดีของการใช้ ChatGPT คือ ChatGPT มีความสามารถทางภาษา สามารถมองรายการคำสำคัญที่ได้ออกมาแล้วบอกชื่อที่เหมาะกับหัวข้อนั้น ๆ ได้. เมื่อเทียบกับการทำ topic modeling แบบข้างต้นที่ผู้วิเคราะห์ต้องดูรายการคำและกำหนดชื่อหัวข้อที่เหมาะสมเอาเอง การใช้ ChatGPT ก็ดูจะสะดวกและช่วยวิเคราะห์ความหมายของหัวข้อให้ได้ด้วย
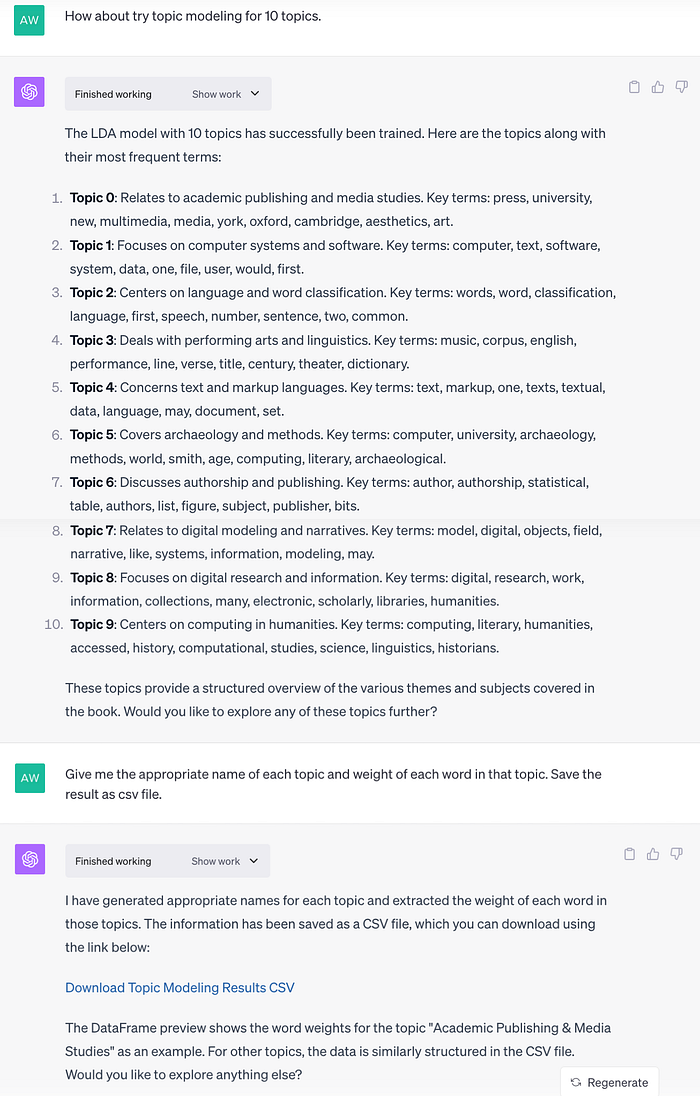
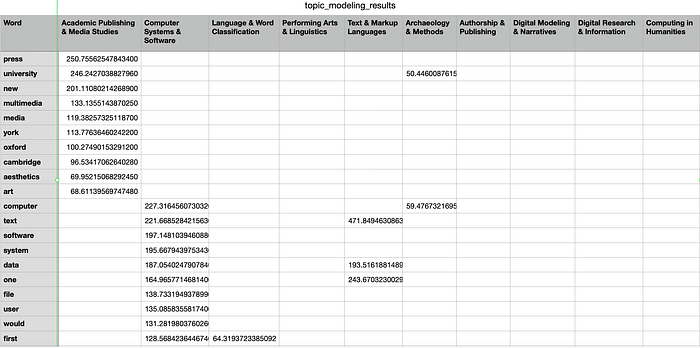
อย่างไรก็ตาม แม้ว่าการใช้ ADA ใน ChatGPT จะช่วยทำ topic modeling ให้ได้สะดวก เพราะสั่งให้ทำงานต่าง ๆ ด้วยภาษาเราเอง. แต่ก็มีข้อจำกัด เช่น การไม่สามารถติดตั้ง library เพิ่มเติมบางอย่างของ NLTK ได้ (ถ้าจะใช้จริงก็ต้องสั่งให้ติดตั้งเองไว้ก่อน), การจำกัดเวลาในการทำงานทำให้หลายครั้งโปรแกรมที่ ADA ทดลองใช้ไม่สามารถทำต่อได้ และที่สำคัญสุด คือ การไม่สามารถอ้างอิงให้รายละเอียดว่าโปรแกรมที่ ADA เขียนให้นั้นทำอะไรบ้าง หากต้องทดลอง run ข้อมูลใหม่อีกครั้งใน ChatGPT ก็อาจไม่ได้ code เดิมมาใช้. เราจึงควรกดดูส่วน Show work เพื่อ copy code ที่ ADA ใช้ หรืออาจสั่งให้ ChatGPT สรุป code ที่ใช้ออกมาแล้ว copy มาทดลองใช้จริงดูว่ามีปัญหาไหม ก่อนที่จะเก็บไว้เพื่อใช้ภายหลัง. ด้วยวิธีการนี้เพื่อจะทำให้มี code ที่สามารถอ้างอิงและใช้งานต่อไปได้
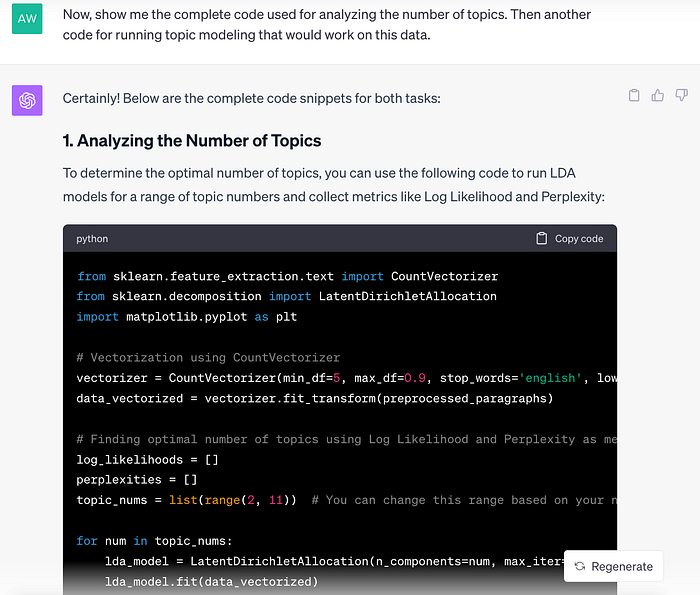
นอกจากการใช้ ChatGPT เพื่อทำ topic modeling โดยตรง เรายังสามารถถามหาความรู้เรื่องต่าง ๆ ที่เกี่ยวข้องได้ เช่น หากอยากรู้ว่ามีวิธีการอะไรที่จะเลือกจำนวนหัวข้อที่เหมาะสม นอกเหนือจากการทดลองใช้จำนวน topic ต่าง ๆ แล้วดูผลที่ได้เอง ChatGPT ก็สามารถแนะและให้ code ที่จะนำไปใช้งานต่อได้

Topic modeling กับภาษาไทย
เนื่องจากการทำ Topic modeling อาศัยการปรากฏร่วมกันของคำเป็นหลักในการคำนวณ โปรแกรมต่าง ๆ ที่ใช้กับภาษาอังกฤษจึงใช้กับภาษาไทยได้ จะมีเพียงรายการคำที่จะเอาออกจากข้อมูลหรือ stop words ที่ต้องแจกแจงในภาษาไทยว่ามีคำอะไรบ้าง ส่วนนี้อาจนำจากรายการคำที่มีคนทำไว้ก่อน หรือถ้าจะดูจากข้อมูลที่มีก็ทำได้ไม่ยาก ให้ประมวลผลนับความถี่คำก่อน จากนั้นดูและเลือกจากรายการคำที่พบบ่อยสุด คำไวยากรณ์มักจะปรากฏอยู่ในรายการคำพบบ่อยอยู่แล้ว
สิ่งที่ควรคำนึงคือการตัดคำก่อนนำข้อมูลมาทำ Topic modeling เพราะโปรแกรมตัดคำแต่ละตัวมีหลักในการตัดคำต่างกัน หากใช้โปรแกรมที่ตัดคำย่อยเกินไป ก็จะทำให้ไม่เห็นคำประสมที่อยากได้ในการทำ Topic modeling (Aroonmanakun, 2018)
อ้างอิง
A gentle introduction to topic modeling using R. (2017, October 06). Retrieved from https://eight2late.wordpress.com/2015/09/29/a-gentle-introduction-to-topic-modeling-using-r
Aroonmanakun, W. (2018). การตัดคำภาษาไทย : ตัดคำอย่างไร — Wirote Aroonmanakun — Medium.
Blei, David M.; Ng, Andrew Y.; Jordan, Michael I (2003). Lafferty, John (ed.). “Latent Dirichlet Allocation”. Journal of Machine Learning Research. 3 (4–5): pp. 993–1022.
Dumais, S. T., Furnas, G. W., Landauer, T. K., Deerwester, S., & Harshman, R. (1988). Using latent semantic analysis to improve access to textual information. CHI ’88: Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. Association for Computing Machinery. doi: 10.1145/57167.57214
Pritchard, J. K.; Stephens, M.; Donnelly, P. (2000). “Inference of population structure using multilocus genotype data”. Genetics. 155 (2): pp. 945–959.
Pykes, K. (2023). What is Topic Modeling? An Introduction With Examples. DataCamp. Retrieved from https://www.datacamp.com/tutorial/what-is-topic-modeling